Video Preview and Facial Recognition in Swift, Part 1: Affine Transforms
Recently I set out to implement Apple’s SquareCam demo app for iOS in Swift. The experience proved interesting for a number of reasons, one of which I’ve already discussed: Swift’s apparent preference for optional chaining in lieu of other error detection and handling mechanisms. Here and in a forthcoming post I turn to the topic of how SwiftSquareCam implements some of its more interesting features.
The entire port required significant efffort, because the original SquareCam demo covers a lot of ground, including
– taking input from either the front or back cameras, if both are present, and providing the user with a switch to toggle between the two;
– displaying a live video preview image of the active camera’s view at any moment;
– implementing basic facial feature recognition and overlaying a rectangular box on faces in the live video preview; and
– taking pictures and saving them to camera roll with their overlays, if any.
Although much of the coding was a straightforward exercise in porting, two areas proved much more challenging: (1) displaying the rectangle overlays on the video preview and (2) saving a picture with overlays. Both require that a still image buffer be captured from the video input; that the facial recognition engine find features; and that the rectangle be scaled, rotated, and otherwise positioned in the appropriate manner. Yet, despite their apparent similarity, these two features are actually implemented quite differently, both in the original SquareCam and in the Swift port. This post will cover how I dealt with the first, displaying rectangles over faces on the live video preview.
Overlays Upon Captured Video Frames
Describing the AVFoundation video output capture framework in its entirety is beyond the scope of this post. (For a conceptual introduction, see Apple’s AVFoundation conceptual programming guide, in particular the chapter entitled Media Capture.) Instead, I skip to the part where the app receives notification that a frame of video data has been captured.
At that time, and after some incantations related to obtaining a reference to the still image associated with the frame, Apple’s demo causes the facial recognition engine to run, which returns an array of zero or more recognized faces. The app then calls a method appropriately named drawFaceBoxesForFeatures to draw rectangles for each recognized face. The rectangles are implemented as separate layers, which are then overlaid upon the video preview layer.
The challenge at this juncture is getting the scale, orientation, and position of the rectangle correct. Each recognized face comes with a bunch of information, including the size of the rectangle bounding it. That size is given in image coordinates, which are defined as those used internally by the still image representation in memory. Image coordinates are distinct from those used to draw on the iOS device’s screen, i.e., those used by layers and views. The latter are sometimes called UIKit coordinates after the relevant iOS library.
At least four factors bear upon the conversion from image to UIKit coordinates. First, image coordinates typically originate at the bottom-left corner, while UIKit coordinates originate at the top-left corner of the iOS screen. Second, when using the front-facing camera, the video preview is mirrored. Third, the preview image of a given is usually a scaled version of its associated still image in memory. Finally, the device orientation may result in additional rotation.
Thus, the conversion from image to UIKit coordinates is often less than straightforward. Perhaps unsurprisingly, this is where Apple’s demo and my Swift implementation part company.
Who Drew What on the Hey Now?
After obtaining the rectangle corresponding to a given recognized face in image coordinates, SquareCam then calls a cryptic user-defined function named videoPreviewBoxForGravity. Unfortunately, this function is not very well documented and is therefore rather difficult to decipher. In addition, Apple’s SquareCam also performs some transformations that don’t seem to conform to the contention that image coordinates originate in the bottom-left corner or, in the case of a mirrored preview when using the front-facing camera, the bottom-right corner. Typically, because I could not follow exactly what actions the Objective-C code took and why it did so, my initial Swift port failed miserably to display rectangles over faces on the video preview.
Affine Transformations to the Rescue
However, I noticed that SquareCam’s final transformation of the preview rectangle, made to account for the orientation of the device, utilized an affine transformation to rotate the rectangle in in a single step. In short, affine transformations are useful in transforming one coordinate system to another; a single augmented matrix can translate, scale, and rotate coordinates all at once. Conveniently enough, Apple has provided a number of useful affine transformation data types and functions. Obviously, affine transformations can be quite useful in graphics processing; for an example, see my co-Hacker Schooler Sarah Kuehnle’s excellent post about working with affine transformations in Swift.
The general equation for transforming cartesian coordinates is as follows:

Our job is to find 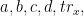

CGAffineTransformMake() function. Here, the problem of transforming a rectangle from image coordinates to UIKit coordinates involved (1) changing the axes appropriately and (2) scaling the rectangle from a 640 x 480 image to whatever size the preview layer took up on the device screen. After performing a number of experiments, I found that the 



and the rectangles should be transformed as follows (before rotating to account for device orientation):


for the unmirrored preview and by

for a mirrored preview, where 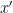
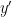

and for the mirrored preview (front-facing camera):

To underscore the utility of these transforms, the following code snipper replaced more than 60-odd lines of code:
var transform = isMirrored ? CGAffineTransformMake(0, heightScaleBy, -widthScaleBy, 0, previewBox.size.width, 0) : CGAffineTransformMake(0, heightScaleBy, widthScaleBy, 0, 0, 0) faceRect = CGRectApplyAffineTransform(faceRect, transform)
Warning: Broken Docs Ahead!
Delving into the documentation (as well as my memory of matrix algebra) proved fruitful, but I came across a painful reminder that Apple’s documentation sometimes falls short. In particular, the section on affine transformations presents an incorrect view of the matrix constructed by the CGAffineTransformMake function. That documentation insists that the following defines an affine transformation:
Fig. 1: Nobody Knows What This Does
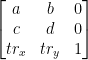
The above matrix is not the augmented matrix required; rather, it is the transpose of the desired matrix!
Next Up
In my next post I’ll address how SwiftSquareCam implemented the functionality to take a picture and save rectangles surrounding recognized faces to the iOS Camera Roll. If you like C function pointers and C-style callbacks, be warned: Swift doesn’t.
Great article.
I was trying to compile the project using Swift 3, several errors triggered.
Do you have an updated version of the project using Swift 3?
Best regards